
I regularly use the Microsoft Windows sysprep tool to create template Windows Server 2012 R2 systems for wider deploy using cloning. Sysprep is used to modify a pre-configured Windows system and create an image or “template” so that you can create unique copies of it for faster system deployment. Failure to use syprep before cloning […]

A little over six months ago I started researching the quickly emerging world of “Hyper-converged” infrastructure as a new IT ethos to take my company’s IT operations into the next decade of application and data hosting. I was first introduced to the idea when I attended a webinar from Simplivity, one of the leading companies […]
Making use of a SAN (storage area network) provides some incredible benefits. I won’t go into depth but at a high-level you often get: 1. Excellent hardware redundancy for data storage, more-so if you are using multiple arrays but even most enterprise single arrays can provide N+1 redundancy. Now we can tolerate power failures, and […]
I have been fiddling about with setting up a SQL Server 2012 Failover cluster using an Equallogic SAN. After a whole lot of digging about I found two different posts on two different sites which got me about 90% of the way there. However there were some key “gotcha’s” and other information that was missing […]
I had a VM using RAW storage format on a ZFS storage object. I needed to delete the RAW hard drive files but couldn’t find them and the “remove” button was greyed out. One post mentioned using “qm rescan” which then allowed the poster to use the remove button but that didn’t work for me. […]
One of the things I like having is a remote system I can access and work on from anywhere. In the past this has meant using either a dedicated server (expensive) or VPS (which is just a VM… too slow). With Proxmox, I figured I had the option of using a container, which would mean […]
If you load Proxmox 4.0 from OVH or any of their affiliates you end up with a partition scheme that gives you one big logical volume for data that is formatted to EXT3. That will work but it isn’t desirable. Starting with Proxmox 3.4, support for the ZFS filesystem was added. ZFS is more than […]
On Thursday I released an article detailing how to get Proxmox setup and also how to configure networking with IPv6. However that article got long and I just said I would address the firewall in the future. Well, that’s today because I need to get the configuration stuff written down before I forget. In addition […]
After beating my head against the wall over the course of many hours I have finally figured out how to get Proxmox working quite well on my cheap KimSufi server… with IPv6. The goal of this article is to document (with varying levels of detail) how to go from a fresh KimSufi, OVH, or SoYouStart […]
Just got my dedicated box from WholesaleInternet.com – 16 Cores – 24 GB of RAM – 3 TB of Hard Drive space – 1 Gbps of bandwidth! Why all that power? Simply put, I want to do virtualization and containers via Proxmox. WholeSaleInternet offers ProxMox 3.1 out the gate – which is a bit outdated. […]
Hyper-V Dynamic Memory Allocation strikes again… I have decided to no longer use Dynamic Memory Allocation on any of my virtual machines. It is a fine idea in theory but it is extremely buggy and I am not sure how it made it into a production OS… What’s the issue this time around? This is […]
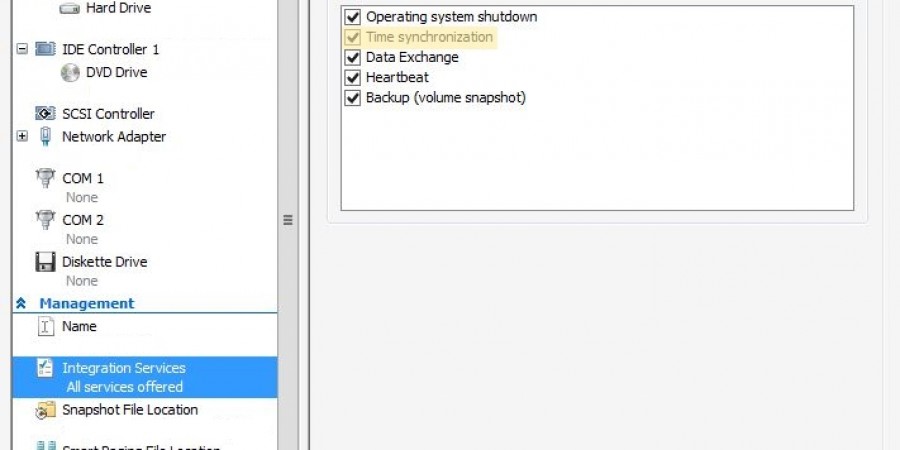
Ran into a fun issue today… I had a pair of Server 2012 R2 servers in a remote office that refused to sync the proper time for their clocks. No matter what I did they were always off by five minutes. One of them was a domain controller for the office. In the process of […]
I had to reconfig my dysfunct home office network today but now everything is setup and talking correctly. I received a 16 port unmanaged switch and 3 USB lan adapters today and all is working correctly with my 3 Server 2012 R2 boxes. The cluster can move forward as soon as I have some more […]
So part of my “poor-man’s hyper-v cluster” experiment in my home office here has led me to start looking into storage options for virtual platforms. Hyper-V is apparently quite flexible, however fail-over clustering limits your options. So for those of you who are just joining us I am doing research on clustered Hyper-V for work. […]